
After over a year I'm trying to get back to posting here... A lot has been going on in my life and I haven't had much time or motivation to work on my own personal stuff.
I have heard of this concept called a "polyglot", a polyglot is a file that's valid in multiple different formats, or source code which compiles/runs in multiple different languages.
But what I'm after this time is not quite that... I want... A chunk of data which displays the same (or similar) string when represented in multiple different encodings (Base64 and ascii). I'm not sure what to call this.
I asked the Cyberia Chat and got a couple different interesting ideas:

OK so a polyglot is a program that runs OK as two different languages
What do you call something which functions the same regardless of whether it's encoded or decoded according to some scheme? (Base64 let's say)...??
And maybe "functions" defined quite loosely, like a "vanity" hash or something, it doesn't have to be exact, just legible
Idk if there is a name for this and now I wanna try to make one, LOL!
"Fixed Point" -> "Vanity Point"

I think eigenvalue is the closest since you are essentially saying you put a value through an encoding and the value remains unchanged , or only changed within certain limits
I think there's a more general term than eigenvalue though, but I'm blanking on it, but also I'm pretty sure most encodings can be phrased as linear algebra anyway, so 🤷♂️
"fixed point", that's the term
How bout a 'vanity point' of a given encoding
How bout a 'vanity point' of a given encoding
Oh I like that!
Homomorphism

yeah the term you're looking for is homomorphism. if f is homomorphic with respect to g then calling f and g is commutative
I'm sorry I would have to go over these math words again
like you can do f first then g , or g first then f. and it would be the same
so if you imagine f is the computation you want to remain the same regardless of whether it's operating on a base64'd input or not, and g is the base64 function, and x is a not-base64'd input, then f(g(x)) = g(f(x))
so if you imagine
fis the computation you want to remain the same regardless of whether it's operating on a base64'd input or not, andgis the base64 function, andxis a not-base64'd input, thenf(g(x)) = g(f(x))
Oooooohhhhh yes so f = user reads the word 'example', g = base64
yep
Makes sense thx
I'm not sure which name I like best,
- A vanity point on the Base64 function
- A value whose legibility is homomorphic over the Base64 function
But regardless, I had already gotten excited and decided I was going to do this, so now I had to figure out how, and where to start.
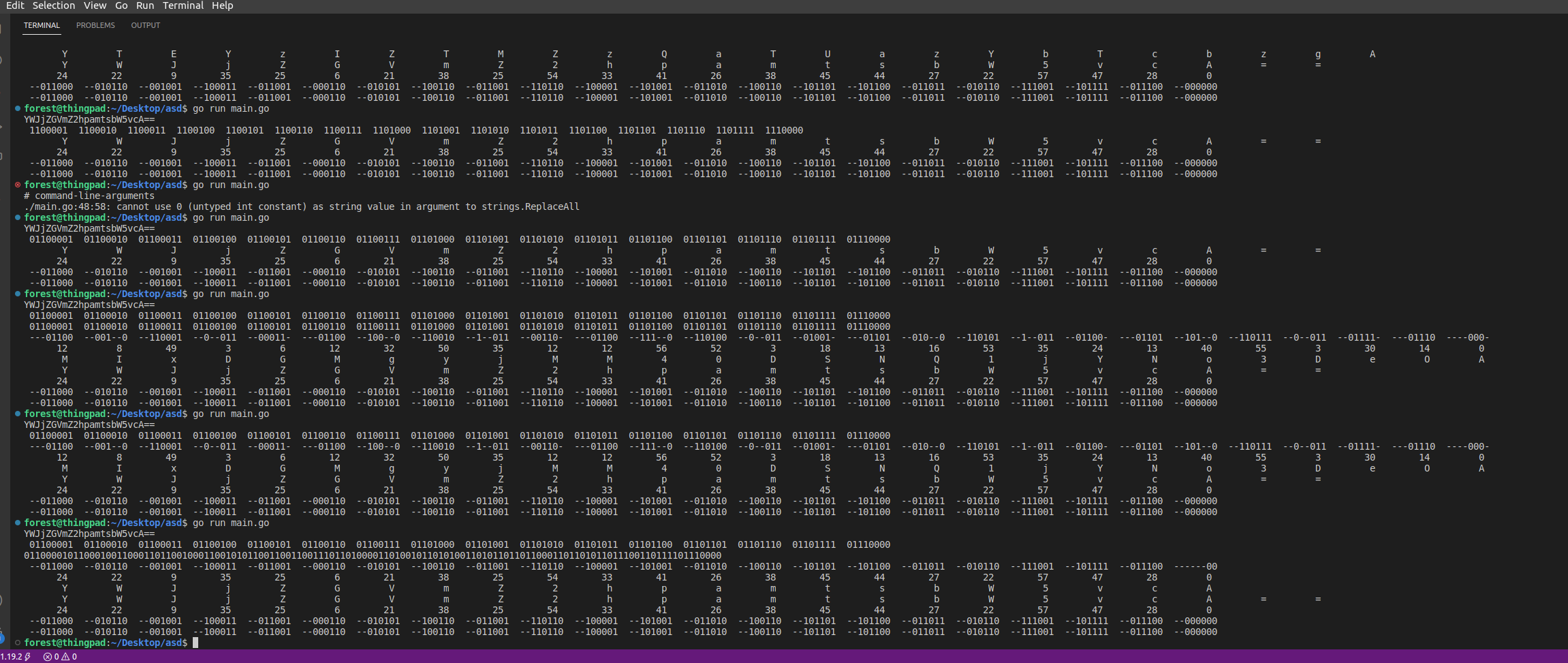
At first, was completely lost on how to do this. I knew would need to visualize the process a bit, so without knowing what my solution was going to end up being, I decided to simply write a program that displays the process of base64 encoding and decoding down to the individual bits involved.
My code would print out the same data from both the encoding perspective and the decoding perspective: as ascii characters, as decimal, and as binary.
During this process I learned a bit more about Base64, stuff that I already knew, but never really felt so viscerally before:
- An ascii character is
1 byte,8 bits - However, only
6 bitsare represented by a single character in a Base64 string.2 ^ 6 = 64
- There is a 3/4 ratio here --
3 bytes = 4 charactersin Base64.- This means (in byte-aligned ascii terms) the bit-wise "meaning" of a given Base64 character will change depending on its position
- Each subsequent character "shifts" the next one by two bits.
Eventually I was able to get my visualization to line up, and I came to a conclusion that seems obvious in retrospect:
The ascii string and Base64 string both represent the exact same binary string, the same bits.
Base64 can represent any bit string... While only some bit strings are valid ascii.
So I needed to try writing out words into a base64 encoded string in different ways, and continually check to make sure that the resulting bits had a valid ascii decoding.
I decided I would:
- Represent the bits as a
stringof1s and0s, since it was more familiar to me. - Check each newly-written 8 bits against a list of valid 8-bit strings for ascii characters.
- Use a recursive function (depth-first-search) to find solutions
- Give my search function multiple different ways to write words into the Base64 encoded string (1337 speak!) so it's less likely to get stuck and never find a solution which has a valid ascii encoding.
var leetSp34k = map[string][]string{
"a": {"4", "@"},
"b": {"6", "8"},
"e": {"3"},
"i": {"1"},
"j": {"7"},
"l": {"1"},
"o": {"0"},
"q": {"9"},
"s": {"$", "5"},
"t": {"+", "7"},
"u": {"v"},
"v": {"u"},
"z": {"2"},
}
I got promising results right away when trying to generate the word Example:
cFExam91
011100000101000100110001011010100110111101100101
cFExam9l
011100000101000100110001011010100110101001
cFExamp
011100000101000100110001011010100110101001001011
cFExampL
011100000101000100110001011010100110101001110101
cFExamp1
011100000101000100110001011010100110101001100101
cFExampl
011100000101101000110111010111
cFo3X
011100000101101000110111010111000000
cFo3XA
011100000101101000110111010111111000
cFo3X4
011100000101101000110111010111111000001100
cFo3X4M
011100000101101000110111010111111000100110
And with a bit of tuning, I was able to churn out much longer strings. Allowing the search function to repeat characters helped it find many more valid solutions and extend the length of strings it could represent:
$ echo 'UjBlOGExamp1elBLOGExamplelBLOGExamplelll' | base64 -d
R0e8a1jjuzPK8a1jjezPK8a1jjezYe
And if we suffix the decoded string with our chosen text, we get at least a basic version of the thing we were originally after: a value that "says the same thing" regardless of whether it's base64 encoded or not:
$ echo 'R0e8a1jjuzPK8a1jjezPK8a1jjezYeBlogExample1BlogExample1BlogExample' | base64 -w 0
UjBlOGExamp1elBLOGExamplelBLOGExamplelllQmxvZ0V4YW1wbGUxQmxvZ0V4YW1wbGUxQmxvZ0V4YW1wbGUK
This "half-and-half" approach is as good as I can do so far, I think... But I would be interested if anyone else has better ideas.
I did also notice some interesting things: some characters seem to work better than others depending on thier position in the string. I noticed t and r to be particularly troublesome: at least with my naive depth-first-search algorithm, I was not able to find a solution for BlogExampleString, but String worked fine.
At any rate, I'm sure there is more to explore, but for now, I'm ready to call it done.
Comments